
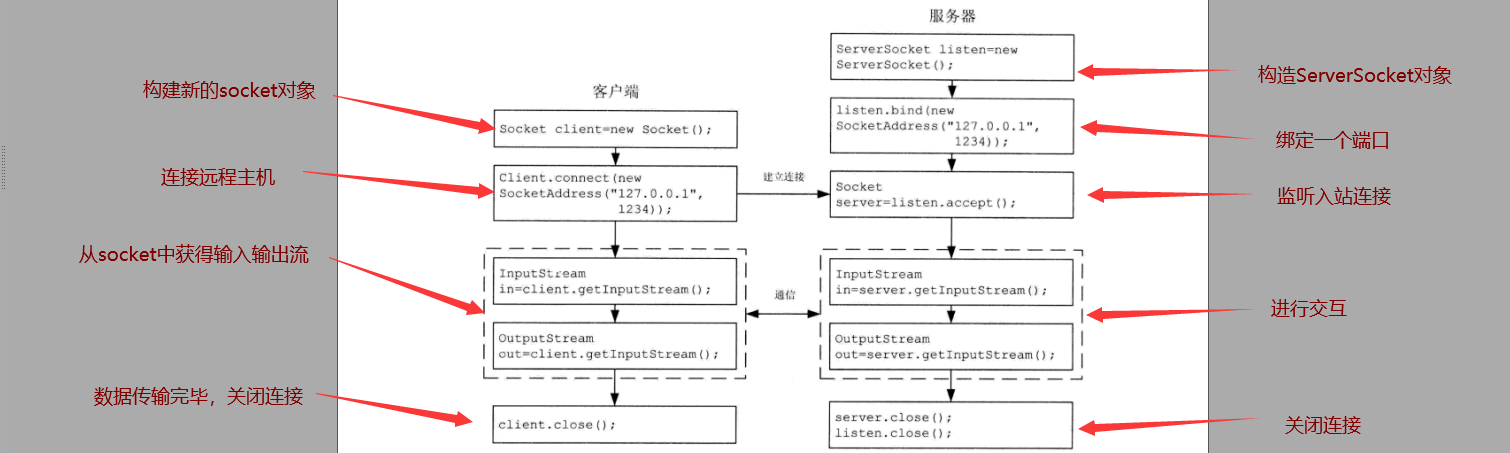
Java基本套接字
基本操作
- 连接远程机器。
- 发送数据。
- 接收数据。
- 关闭连接。
- 绑定端口。
- 监听入站数据。
- 在所绑定端口.上接受来自远程机器的连接。
其中,前四项用于客户端,后六项用于服务器,最后三项只有服务器才需要,即等待客
户端的连接,这些操作通过ServerSocket类实现。
Java NIO基础
概述
NIO解决一客户一线程所带来的开销大的问题
所谓一客户一线程是指,多个客户端访问同一个服务器进程时,服务器需要为每个请求创建一个服务线程
并且非堵塞是NIO实现的重要功能之一,为了实现非堵塞,NIO引入了
- 选择器 Selector
- 通道 Channel
通道表示到实体(如硬件设备、文件、网络套接字或者可以执行一个或多个不同的的IO操作)的程序组件开放连接通道可以注册一个选择器实例,通过该实例的select方法,用户可以询问“在一个或一组通道中,哪一个是当前需要的服务(即被读、写或被接受)“
在一个准备好的通道执行相应的I/O操作,就不需要等待,也就不会堵塞了
NIO与IO的区别
| I0 | NIO |
|---|---|
| 面向流(Stream Oriented) | 面向缓冲区(Buffer Oriented) |
| 阻塞I0(Blocking I0) | 非阻塞I0(Non Blocking I0) |
| (无) | 选择器(Selectors) |
缓冲区
NIO中一个主要的特性是java.nio.Buffer。缓冲区(Buffer)提供了一个比流抽象的、更高效和可预测的I/O。Buffer 代表了一个有限容量的容器一其本质是一个数组,通道Channel使用Buffer实例来传输数据
Buffer包含4个索引
- capacity: 缓冲区总容量,可通过Buffer.capacity获取,并且是不可修改
- position: 缓冲区位置,即下一个要写入或读取的索引,获取/设置通过position()/position(int)
- limit: 缓冲区限制,即第一个不应该读取或写入的位置,获取/设置通过limit()/limit(int)
- mark: 缓冲区位置标记,通过mark()设置一个位置,reset()方法被调用后,position被置为mark
遵循如下规则
0 ≤ mark ≤ position ≤ limit ≤ capacity
ByteBuffer的创建
1 | //直接创建缓冲区 |
这种方式与流的区别:流是单向的,而这种方式看读可写
ByteBuffer的读写
put()/get()方法:基于相对位置和绝对位置的读写
基于相对位置就是基于目前缓冲区位置position的当前值,从“下一个”位置读取或存放数据,并为position增加适当的值。绝对位置的put)/get()方法,必须提供写入/读出的位置, 该方式的读写操作,不改变position的值
1 | //相对位置 |
需要注意的是 ,部分数据的get()/put()是不允许的。以写人
为例,如果要写入的数据量超过当前缓冲区允许写入的数据量(可通过Buffer.remaining()
方法获得该值),则所有的数据都不会写入缓冲区,position的位置不变,put()方法抛出
BufferOverflowException异常。
工具方法
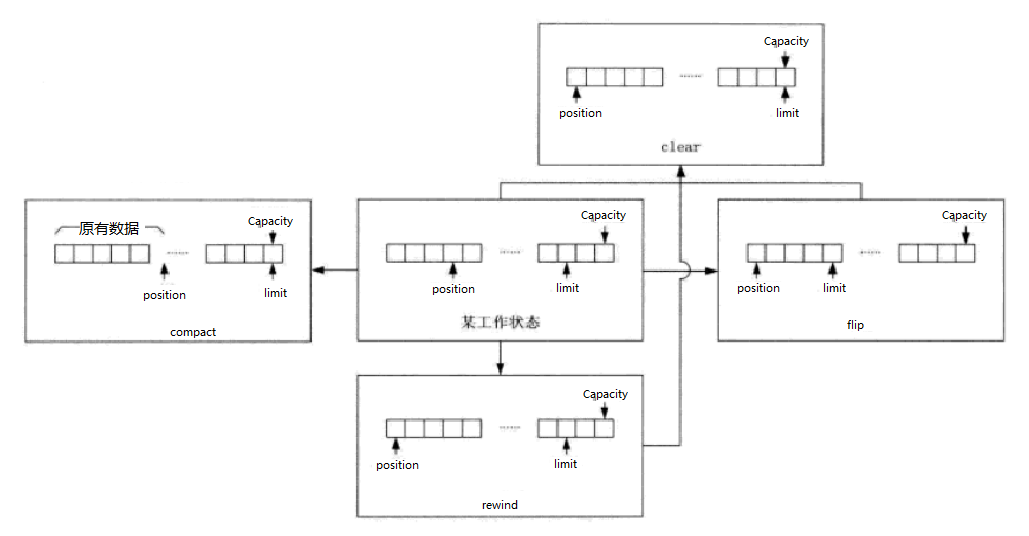
clear() 通过clear()方法,缓冲区的poistion被设置为0, limit 设置为capacity,这样,缓冲区准备好接收新数据。后续的put()/readO调用,将数据从第-一个元素开始填入缓冲区,最多直到填满该缓冲区,达到limit位置(等于capacity)。
flip()方法用于将缓冲区准备为数据传出状态,该方法将limit设置为position后,将
position 设置为0。后续的get()/write()方法将从缓冲区的第一个元素开始传出数据,直到
limit位置。通过fip0方法和get(/write()方法配合,可以将前面利用put()/read)方法放入
缓冲区的所有数据读出(一直读到limit)。rewind)方法将position设置为0,但不改变limit的值,如果需要多次读取缓冲区里的
数据,可以在两次读取间使用rewind()方法。compact()方法将position和limit间的数据复制到缓冲区的开始位置,为后续的put()/
read()调用让出空间。调用结束后,poistion的值被设置为数据的长度,也就是原来的limit
减去position的值,而limit则设置为capacity。和clear()、fip() 等方法不同,compact() 不但改变了position 和limit的位置,还改变了缓冲区中的数据。compact()主要用于在缓冲区中还有未写出的数据时,为读入数据准备空间:即在write()方法调用后和添加新数据的read)方法前调用compact()方法,将未写出的“剩余”数据移动到缓冲区前面,为后面read()方法提供释放空间。在图中,假设write()方法调用后,缓冲区处于“某工作状态”,这时,position 到limit间的数据为未写出的“剩余”数据,而limit到capacity的空间则是read)方法可以使用的空间,通过compact()操作,position 到limit 间的数据被挪到缓冲区的前面,position 的位置也被设置为“剩余”数据长度。接下来,开发人员就可以直接调用read0/put0方法,从position位置开始放入数据。该数据和原来的“剩余”数据- -起,构成了连续的可用数据。
Buffer还支持一些其他功能,如直接缓冲区(directbuffer)、Java基本类型的put()/get()、缓冲区共享、复制、透视、字符编码转换等
通道
一个Channel的实例代表一个 和设备的 连接
对象的创建
ServerSocketChannel/SocketChannel通过工厂方法创建
1 | public static SocketChannel open() throws IOException |
SocketChannel创建后,可以通过connect()连接到远程机器,通过close()关闭连接,这
些操作和Socket的没有什么差别。
数据的读写
1 | public int read (ByteBuffer dst) |
和socket类似的操作,可以通过socket方法获取ServerSocket对象
1 | public SocketChannel accept () |
是否支持工作在非阻塞状态
Buffer使用阻塞方法相对于基本套接字没有什么优点
1 | public SelectableChannel configureBlocking (boolean block) //设置堵塞 |
非阻塞的SocketChannel 的connect()方法会立即返回,用户必须通过isConnected()判断连接是否已经建立,或者通过finishConnect()方法在非阻塞套接字上阻塞等待连接成功:非阻塞的read(),在Socket上没有数据的时候,立即返回(返回值为0),不会等待;非阻塞的acceptO,如果没有等待的连接,将返回null
1 | public boolean isConnected () |
选择器
选择器(Selector) 的使用方法:通过静态的工厂方法创建Selector实例,通过Channel
的注册方法,将Selector实例注册到想要监控的Channel实例上,最后调用选择器的select()
方法。该方法会阻塞等待,直到有一个或多个通道准备好I/O操作或超时。select() 方法将返
回可进行I/O操作的通道数量。现在,在一个单独的线程中,就可以检查多个通道是否可以
进行I/O操作,不需要为每一一个通道都准备一个线程了。
选择器的打开关闭
1 | public static Selector open () |
获取/设置标志位
选择器注册标记SelectionKey维护联的信息保存在java.nio.channels.SelectionKey实例中
- OP_ READ (通道上有数据可读)
- OP_ WRITE (通道已经可写)
- OP_ CONNECT (通道连接已建立)
- OP_ ACCEPT (通道上有连接请求)
1 | public int interestOps () |
SeverSocketChannel/SocketChannel配合工作的API
1 | public SelectionKey register (Selector sel, int ops) // 注册 |
选择器实例selector.上注册了- -个SocketChannel对象,支持读操作
1 | SelectionKey readKey = channel . register (selector, SelectionKey.OP_READ) |
注销/获取选择器
1 | Selector selector () //获取选择器 |
select方法
1 | /**如果发现select()的返回值大于0,表明有需要处理的I/O事件发生**/ |
获取相关建的方法
1 | public Set<SelectionKey> keys () //selector上已注册的所有键 |
Hadoop IPC上的使用
判断通道上等待操作的方法
1 | public int readyOps () |
与附件有关的另外两个方法
1 | public Object attach (object ob) //添加附件 |
以上内容来自《Hadoop技术内幕 深入解析HADOOP COMMON和HDFS架构设计与实现原理》



