
什么是大数据
百度百科的定义,大数据(BIG DATA),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产
在目前的业界尚未对大数据由清晰明确的定义, 它的第一次出现是在麦肯锡公司的报告中出现的, 在维基百科上的较为模糊的定义是很难运用软件的手段获取大量的内容信息, 对其处理后整理得出的数据集合。其他计算机学科的学者给出的定义是数据的尺度极为巨大, 常规的数据处理软件无法对数据识别、存储和应用的海量数据信息
维基百科的定义,大数据是指无法在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集合。
研究机构Gartner定义,“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
数据单位
1MB = 1024KB、1GB = 1024MB
1TB = 1024GB、1PB = 1024TB
大数据的特征
- 容量(Volume):数据的大小决定所考虑的数据的价值和潜在的信息;
- 种类(Variety):数据类型的多样性;
- 速度(Velocity):指获得数据的速度;
- 可变性(Variability):妨碍了处理和有效地管理数据的过程。
- 真实性(Veracity):数据的质量
- 复杂性(Complexity):数据量巨大,来源多渠道
- 价值(value):合理运用大数据,以低成本创造高价值
大数据相关技术
- 数据采集: OLAP(联机分析处理)和数据挖掘的基础。ETL工具负责将分布的、异构的数据源进行抽取,抽取到中间层,进行清洗、转换、集成,(不过对于负责的逻辑处理不会这么干,用Spark或者其他的进行处理),最后放到数据仓库中存储,如Hive
- 数据存取: 关系型数据库、NoSQL(Not Only SQL,泛指非关系型数据库),SQL等
- 基础架构: 云存储、分布式文件存储等
- 数据处理: 自然语言处理(Natural Language Processing, NLP)
- 数据分析: 假设检验、显著性检验、差异检验、差异分析、相关性分析、T检验、方差分析、卡方分析、偏相关性分析、距离分析、回归分析、简单回归分析、多元回归分析、逐步回归、预测和残差分析、岭回归、Logistic回归分析、曲线估计、因子分析、聚类分析、主成分分析、判别分析、对应分析、快速聚类和聚类法、对应分析、多元对应分析等
- 数据挖掘: 分类(Classification)、估计(Estimation)、预测(Prediction)、相关性分析或关联规则(Association)、复杂数据类型挖掘(Text、Web、图形图像、视频、音频等)
- 模型预测: 预测模型、机器学习、建模仿真
- 结果呈现: 云计算、标签云、关系图等
大数据带来的变革
大数据小故事
最早关于大数据的故事发生在美国第二大的超市塔吉特百货(Target)。孕妇对于零售商来说是个含金量很高的顾客群体。但是他们一般会去专门的孕妇商店而不是在Target购买孕期用品。人们一提起Target,往往想到的都是清洁用品、袜子和手纸之类的日常生活用品,却忽视了Target有孕妇需要的一切。那么Target有什么办法可以把这部分细分顾客从孕妇产品专卖店的手里截留下来呢?
为此,Target的市场营销人员求助于Target的顾客数据分析部的高级经理Andrew Pole,要求他建立一个模型,在孕妇第2个妊娠期就把她们给确认出来。在美国出生记录是公开的,等孩子出生了,新生儿母亲就会被铺天盖地的产品优惠广告包围,那时候Target再行动就晚了,因此必须赶在孕妇第2个妊娠期行动起来。如果Target能够赶在所有零售商之前知道哪位顾客怀孕了,市场营销部门就可以早早的给他们发出量身定制的孕妇优惠广告,早早圈定宝贵的顾客资源。
可是怀孕是很私密的信息,如何能够准确地判断哪位顾客怀孕了呢?Andrew Pole想到了Target有一个迎婴聚会(baby shower)的登记表。Andrew Pole开始对这些登记表里的顾客的消费数据进行建模分析,不久就发现了许多非常有用的数据模式。比如模型发现,许多孕妇在第2个妊娠期的开始会买许多大包装的无香味护手霜;在怀孕的最初20周大量购买补充钙、镁、锌的善存片之类的保健品。最后Andrew Pole选出了25种典型商品的消费数据构建了“怀孕预测指数”,通过这个指数,Target能够在很小的误差范围内预测到顾客的怀孕情况,因此Target就能早早地把孕妇优惠广告寄发给顾客。
那么,顾客收到这样的广告会不会吓坏了呢?Target很聪明地避免了这种情况,它把孕妇用品的优惠广告夹杂在其他一大堆与怀孕不相关的商品优惠广告当中,这样顾客就不知道Target知道她怀孕了。百密一疏的是,Target的这种优惠广告间接地令一个蒙在鼓里的父亲意外发现他高中生的女儿怀孕了,此事甚至被《纽约时报》报道了,结果Target大数据的巨大威力轰动了全美。
根据Andrew Pole的大数据模型,Target制订了全新的广告营销方案,结果Target的孕期用品销售呈现了爆炸性的增长。Andrew Pole的大数据分析技术从孕妇这个细分顾客群开始向其他各种细分客户群推广,从Andrew Pole加入Target的2002年到2010年间,Target的销售额从440亿美元增长到了670亿美元。
我们可以想象的是,许多孕妇在浑然不觉的情况下成了Target常年的忠实拥泵,许多孕妇产品专卖店也在浑然不知的情况下破产。浑然不觉的背景里,大数据正在推动一股强劲的商业革命暗涌,商家们早晚要面对的一个问题就是:究竟是在浑然不觉中崛起,还是在浑然不觉中灭亡
其他故事
大数据初步学习路线
| 技术 | 工具 |
|---|---|
| JAVA | 面向对象的编程语言 |
| Linux | 类Unix操作系统 |
| Hadoop生态圈 | |
| 1、HDFS | 解决存储问题 存储极大数目的信息(terabytes or petabytes),将数据保存到大量的节点当中。支持很大单个文件。提供高可靠性,是指一个或多个节点故障,系统仍然可以继续工作 提供数据快速访问 |
| 2、MapReduce | 解决计算问题 它有个特点就是不管多大的数据只要给它时间它就能把数据跑完,但是时间可能不是很快所以它叫数据的批处理 |
| 3、Yarn | 资源调度器 |
| 4、ZooKeeper | 分布式应用程序协调服务 一般用于存储一些相互协作的一些信息 |
| 5、Flume | 数据采集工具 |
| 6、Hive | 基于Hadoop的数据仓库工具 |
| 7、Hbase | 分布式应用程序协调服务 一般用于存储一些相互协作的一些信息 |
| 8、Sqoop | 数据传递工具,如将数据从关系型数据库导入Hive |
| Scala | 多范式编程语言、面向对象和函数式编程的特性 |
| Spark | 目前企业常用的批处理离线数据/实时计算引擎 它是用来弥补基于MapReduce处理数据速度上的缺点,它很是流氓,直接将数据存在内存中 【注意】 MapReduce运行时也是需要将代码数据加载到内存中的,只不过Spark都是基于内存操作 |
| Flink | 目前最火的流式处理框架、既支持流处理、也支持批处理 |
| Elasticsearch | 大数据分布式弹性搜索引擎 |
大数据处理流程
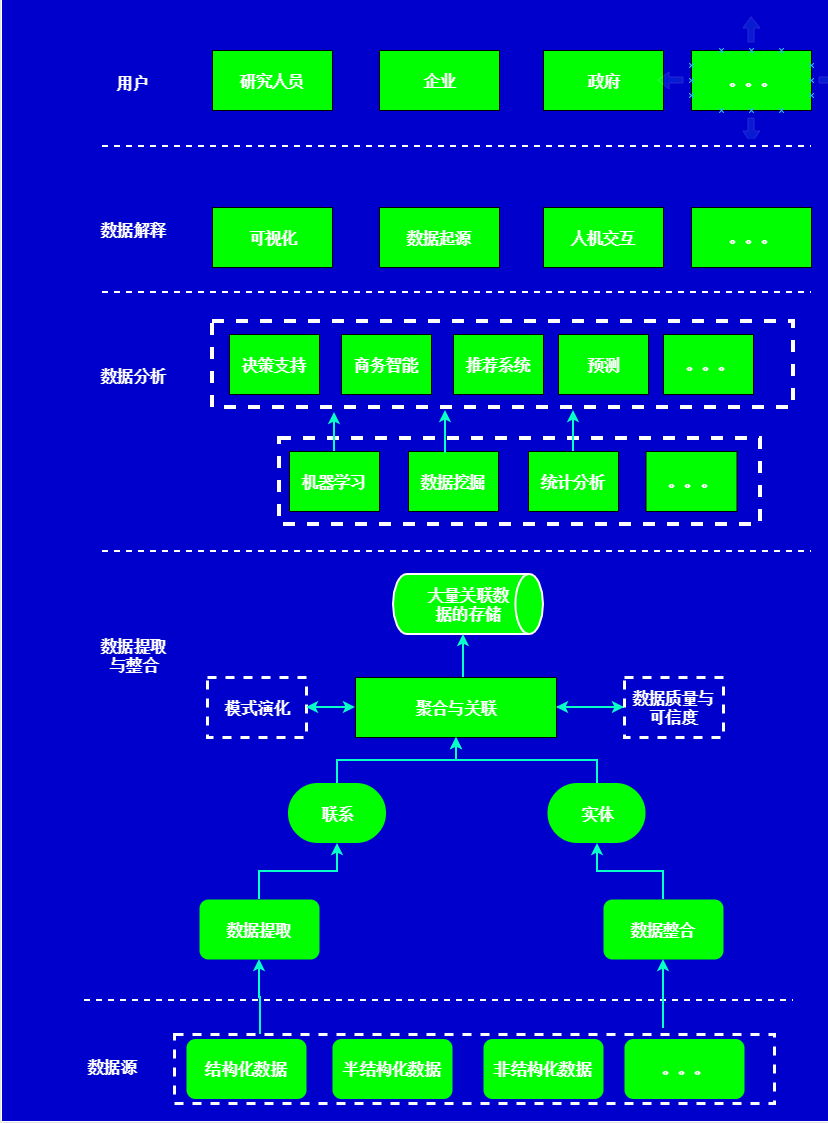
大数据处理模型
按照数据的三状态定义
- 水库里一平如镜的水—>静止数据(data at rest)
- 水处理系统中上下翻滚的水—>正在使用的数据(data in use)
- 汹涌而来的新水流—>动态的水(data in motion)
“快”说的是两层面
- “动态数据” 来得快
- “正在使用的数据” 处理得快
- 批处理 MapReduce
- 流处理 Spark Streaming
科普
根据国际数据公司(IDC)的《数据宇宙》报告显示:2008年全球数量为0.5ZB,2010年为1.2ZB,人类正式进入ZB时代。更为惊人的是,2020年以前全球数据量仍将保持每年40%多的高速增长,大约每两年就翻一倍,这与IT界的摩尔定律极为相似,姑且称之为“大数据爆炸定律”。



