序列化介绍
序列化是一种将对象的状态信息转化成可以存储或者传输的过程,与之相反的为反序列化序列化的用途
作为一种持久化格式。对象序列化后存盘
作为一种通信的数据格式。如虚拟机之间通信
作为一种拷贝、克隆机制。放缓存
Java序列化
Java通过实现Serializable接口
1 2 3 4 5 6 7 import java. io.Serializable ;/**定义一个可以序列化的 App 信息类. */ public class Appinfo implements Serializable //序列化标识 private static final long serialVersionUID = 11 ; }
Hadoop 不使用Java序列化原因
Java 自带的序列化机制占用内存空间大,额外的开销会导致速度降低,Hadoop对序列化的要求较高,需要保证序列化速度快、体积小、占用带宽低等特性
Hadoop 序列化机制是将对象序列化到流中,而 Java 序列化机制是不断创建新对象,对于MapReduce应用来说,不能重用对象
Java序列化在反序列化时,有可能需要访问前一个数据,这将导致数据无法分割来通过MapReduce来处理
Hadoop 序列化
在 Hadoop 序列化机制中,org.apache.hadoop.io包中定义了大量的可序列化对象
Hadoop 序列化机制通过调用write方法(它带有一个类型为DataOutput的参数),将对象序列化到流中
Hadoop 反序列化通过对象的readFields从流中读取数据
Hadoop序列化机制的特征
对于处理大数据的Hadoop平台,其序列化需要具备以下特征
紧凑。这样可以充分利用Hadoop集群的资源,hadoop集群中最稀缺的是资源
快速。进程通信时会大量使用序列化机制,因此需要减少序列化开销
可扩展性。为适应发展,序列化机制也需要支持这些升级和变化
互操作。支持不同语言开发
Hadoop Writable机制
Hadoop序列化都必须实现该接口
均实现Wriable接口的两个函数,1 2 (1) write:将对象写入字节流: (2) readFields:从字节流中解析出对象。
例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 /** * BlockWritable有三个对象, * write方法将三个对象写到流中 * readFields从流中读出三个对象 */ public class BlockWritable implements Writable { private long blockId; private long numBytes; private long generationStamp; /** * 输出序列化对象到流中 * @param out * @throws IOException */ @Override public void write(DataOutput out) throws IOException { out.writeLong(this.blockId); out.writeLong(this.numBytes); out.writeLong(this.generationStamp); } /** * 从流中读取序列化对象 * 为了效率,尽可能复用现有对象 * @param in 从该流中读取数据 * @throws IOException */ @Override public void readFields(DataInput in) throws IOException { this.blockId = in.readLong(); this.numBytes = in.readLong(); this.generationStamp = in.readLong(); if (this.numBytes < 0L) { throw new IOException("Unexpected block size: " + this.numBytes); } } }
Hadoop序列化的其它几个接口
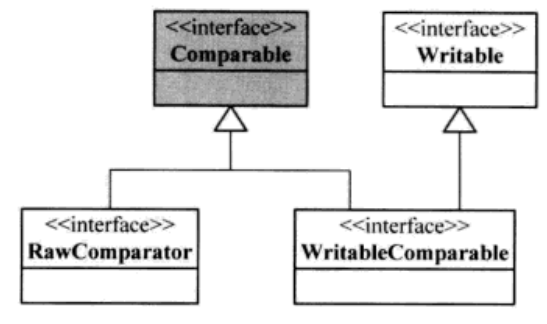
WritableComparable
RawComparator
RawComparator允许执行者 比较 流中读取的未被反序列化为对象的 记录,从而省去创建对象所带来的开销
1 2 3 4 5 6 7 8 9 10 11 int compare (byte [] var1, int var2, int var3, byte [] var4, int var5, int var6)
WritableComparator
在RawComparator中WritableComparator是个辅助类,实现了RawComparator接口以DoubleWritable为例
1 2 3 4 5 6 7 8 9 10 11 public static class Comparator extends WritableComparator public Comparator () super (DoubleWritable.class); } public int compare (byte [] b1, int s1, int l1, byte [] b2, int s2, int l2) double thisValue = readDouble(b1, s1); double thatValue = readDouble(b2, s2); return thisValue < thatValue ? -1 : (thisValue == thatValue ? 0 : 1 ); } }
WritableComparator是RawComparator对WritableComparable类的一一个通用实现。提供两个主要功能。首先,提供了一个RawComparator的compare()默认实现,该实现从数据流中反序列化要进行比较的对象,然后调用对象的compare()方法进行比较(这些对象都是Comparable的)。其次,它充当了RawComparator实例的一个工厂方法,通过DoubleWritable获得RawComparator的代码如下
1 RawComparator<DoubleWritable> comparator = WritableComparator.get(DoubleWritable.class);
RawComparator和WritableComparable的类图
Hadoop 序列化的类 java基本类型的封装
说明:
这些类实现了WritableComparable接口
VIntWritable和VLongWritable是只可变长
可变长的格式更空间
VIntWritable可用VLongWritable读入
变长整型分析
writeVLong ()方法实现了对整型数值的变长编码,它的编码规则如下:
如果是正数,则编码值范围落在-113和-120间(闭区间),后续字节数可以通过-(v+112)计算。
如果是负数,则编码值范围落在-121和-128间(闭区间),后续字节数可以通过-(v+120)计算。
后续编码将高位在前,写入输入的整数(除去前面全0字节)。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public static void writeVInt (DataOutput stream, int i) throws IOException writeVLong(stream, (long )i); } public static void writeVLong (DataOutput stream, long i) throws IOException if (i >= -112L && i <= 127L ) { stream.writeByte((byte )((int )i)); } else { int len = -112 ; if (i < 0L ) { i = ~i; len = -120 ; } for (long tmp = i; tmp != 0L ; --len) { tmp >>= 8 ; } stream.writeByte((byte )len); len = len < -120 ? -(len + 120 ) : -(len + 112 ); for (int idx = len; idx != 0 ; --idx) { int shiftbits = (idx - 1 ) * 8 ; long mask = 255L << shiftbits; stream.writeByte((byte )((int )((i & mask) >> shiftbits))); } } }
ObjectWritable
针对Java基本类型、字符串、枚举、Writable、空值、Writable的其 他子类,ObjectWritable提供了一个封装,适用于字段需要使用多种类型。ObjectWritable 可应用于Hadoop远程过程调用中参数的序列化和反序列化; ObjectWritable 的另一个典型应用是在需要序列化不同类型的对象到某-个字段,如在一个SequenceFile 的值中保存不同类型的对象( 如LongWritable值或Text值)时,可以将该值声明为ObjectWritable。
ObjectWritable的实现比较冗长,需要根据可能被封装在ObjectWritable中的各种对象进行不同的处理。ObjectWritable 有三个成员变量,包括被封装的对象实例instance、该对象运行时类的Class对象和Configuration对象。
1 2 3 private Class declaredClass;private Object instance;private Configuration conf;
ObjectWritable的write 方法调用的是静态方法ObjectWritable.writeObject(),该方法可以往DataOutput接口中写入各种Java对象。
writeObject()方法先输出对象的类名(通过对象对应的Class对象的getName()方法获得),
1 UTF8.writeString(out, declaredClass.getName());
然后根据传入对象的类型,分情况系列化对象到输出流中,也就是说,对象通过该方法输出对象的类名,对象序列化结果对到输出流中。在ObjectWritable. writeObject(的逻辑中,需要分别处理null Java 数组、字符串String、Java 基本类型、枚举和Writable的子类6种情况,由于类的继承,处理Writable时,序列化的结果包含对象类名,对象实际类名和对象序列化结果三部分。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 public void write (DataOutput out) throws IOException writeObject(out, this .instance, this .declaredClass, this .conf); } public static void writeObject (DataOutput out, Object instance, Class declaredClass, Configuration conf) throws IOException writeObject(out, instance, declaredClass, conf, false ); } public static void writeObject (DataOutput out, Object instance, Class declaredClass, Configuration conf, boolean allowCompactArrays) throws IOException if (instance == null ) { instance = new ObjectWritable.NullInstance(declaredClass, conf); declaredClass = Writable.class; } if (allowCompactArrays && declaredClass.isArray() && instance.getClass().getName().equals(declaredClass.getName()) && instance.getClass().getComponentType().isPrimitive()) { instance = new Internal(instance); declaredClass = Internal.class; } UTF8.writeString(out, declaredClass.getName()); if (declaredClass.isArray()) { int length = Array.getLength(instance); out.writeInt(length); for (int i = 0 ; i < length; ++i) { writeObject(out, Array.get(instance, i), declaredClass.getComponentType(), conf, allowCompactArrays); } } else if (declaredClass == Internal.class) { ((Internal)instance).write(out); } else if (declaredClass == String.class) { UTF8.writeString(out, (String)instance); } else if (declaredClass.isPrimitive()) { if (declaredClass == Boolean.TYPE) { out.writeBoolean((Boolean)instance); } else if (declaredClass == Character.TYPE) { out.writeChar((Character)instance); } else if (declaredClass == Byte.TYPE) { out.writeByte((Byte)instance); } else if (declaredClass == Short.TYPE) { out.writeShort((Short)instance); } else if (declaredClass == Integer.TYPE) { out.writeInt((Integer)instance); } else if (declaredClass == Long.TYPE) { out.writeLong((Long)instance); } else if (declaredClass == Float.TYPE) { out.writeFloat((Float)instance); } else if (declaredClass == Double.TYPE) { out.writeDouble((Double)instance); } else if (declaredClass != Void.TYPE) { throw new IllegalArgumentException("Not a primitive: " + declaredClass); } } else if (declaredClass.isEnum()) { UTF8.writeString(out, ((Enum)instance).name()); } else if (Writable.class.isAssignableFrom(declaredClass)) { UTF8.writeString(out, instance.getClass().getName()); ((Writable)instance).write(out); } else { if (!Message.class.isAssignableFrom(declaredClass)) { throw new IOException("Can't write: " + instance + " as " + declaredClass); } ((Message)instance).writeDelimitedTo(DataOutputOutputStream.constructOutputStream(out)); } }
和输出对应,ObjectWritable 的readFields()方法调用的是静态方法ObjectWritable.readObject(),该方法的实现和writeObject()类似,唯一值得研究的是Writable对象处理部分,readObject ()方法依赖于WritableFactories类。WritableFactories 类允许非公有的Writable子类定义一一个对象工厂,由该工厂创建Writable对象,如在上面的readObject()代码中,通过WritableFactories的静态方法newInstance(),可以创建类型为instanceClass的Writable子对象。具体查看org.apache.hadoop.io.WritableFactories类
注:ObjectWritable它比较浪费资源,可以使用静态数组来记录数据类型以提高效率
1 2 3 1. 减少垃圾回收:从流中反序列化数据到当前对象,重复使用当前对象,减少了垃圾回收GC ; 2. 减少网络流量 : 序列化和反序列化对象类型不变 ,因此可以只保存必要的数据来减少网络流量; 3. 提升 I/O 效率 : 由于序列化和反序列化的数据量减少了,配合Hadoop压缩机制,可以提升I/O效率。